Everybody complains about the weather, but nobody does anything about it.
Frustrated trying to find ancestors in the 1950 Census? Let ORA help!
It's frustrating to use the search page for the 1950census.archives.gov site. The AI-generated name index leaves a lot to be desired compared to transcriptions created manually. To be fair, it's a difficult problem to solve with technology alone. Unfortunately, there are issues with the implementation of the search results page that exacerbate the challenges with the name index. ORA alleviates some of those issues.
Example without ORA
Let's consider an example. I'd like to find George Anderson who lived in Saugus, Essex County, Massachusetts, in 1950. I do not know the address. His wife's name is Dorothy and there should be a few children in the household, too.
I suggest you work through this example. You do not need an ORA subscription to do so.
On the 1950 Census search page, I set the state to "Massachusetts", the County/City to "Essex" and the name to "George Anderson".
The search page performance is quite impressive considering the load it must be under given the popularity of the site with US-based family researchers. The search page structure and content is less impressive.
Issue: The search results are difficult to scan.
That's a major issue when the name index is likely to return many, many false positives. With 25 results per page, it takes me 10 mouse clicks to scroll through all the entries. Primarily, I'm scanning to see the "Matched Name(s)". Secondarily, if the matched name looks promising, I'd like to review the other people on the page to see if the household includes both George and Dorothy.
Scrolling through ten screen-fulls is time-consuming and error-prone. When the matched name seems promising, I scan the "Machine Learning (AI) Extracted Names" and that is (again) time-consuming and error-prone.
I do not find any entries of interest. There are a few matched names that include both George and Anderson, but there are plenty with only one or the other. I am not sure how the site weights the search results, but I am surprised that the names that match both terms are not always the first entries in the results.
Issue: The search terms are ORed and names that match all terms are not given priority in the result list.
Including "George" matches too many people because the search terms are ORed, a name with any of the words is a match.
I decide to adjust my search terms. The current results include a lot of people without the surname Anderson and there are too many people named George in the results. With loose-matching on an imperfect name index, there are 3,234 entries, far too many to review and I am not confident that the first entries in the list are more likely to be matches than the last entries in the list.
I change the name search to just "Anderson". This reduces the search results to 240 entries. This is a case where less is more, or more accurately, less is more effective.
240 results is still too many. That's ten pages of results to scan. If I knew the Enumeration District, that would really help. However, I do not know George's address within Saugus, and the search page doesn't support restricting the search to the thirty or so Enumeration Districts in Saugus. I do know from reviewing ED lists that all the Saugus entries are in the range 5-433 to 5-457. That fact will come in handy later.
I start scanning the results. Eventually, I find George and his wife Dorothy on page 7 of the results.
Ouch! That was painful, and it could have been worse. If George or Dorothy's names were transcribed poorly, that would increase the chances that I would not notice the correct entry when scanning the results.
Example with ORA
Now let's repeat the example but with ORA helping us. If you do not have ORA, you will not be able to see the summary table that is the focus of the assistance it provides so I have included several screenshots.
I skip the first search I did above, where I set state to "Massachusetts", County/City to "Essex" and name to "George Anderson". I know now that less is usually more with the 1950 Census site.
I repeat the second search, setting state to "Massachusetts", County/City to "Essex" and name to "Anderson". ORA adds a summary table to the top of the result list:
(Click the image to open a larger version in a new window.)
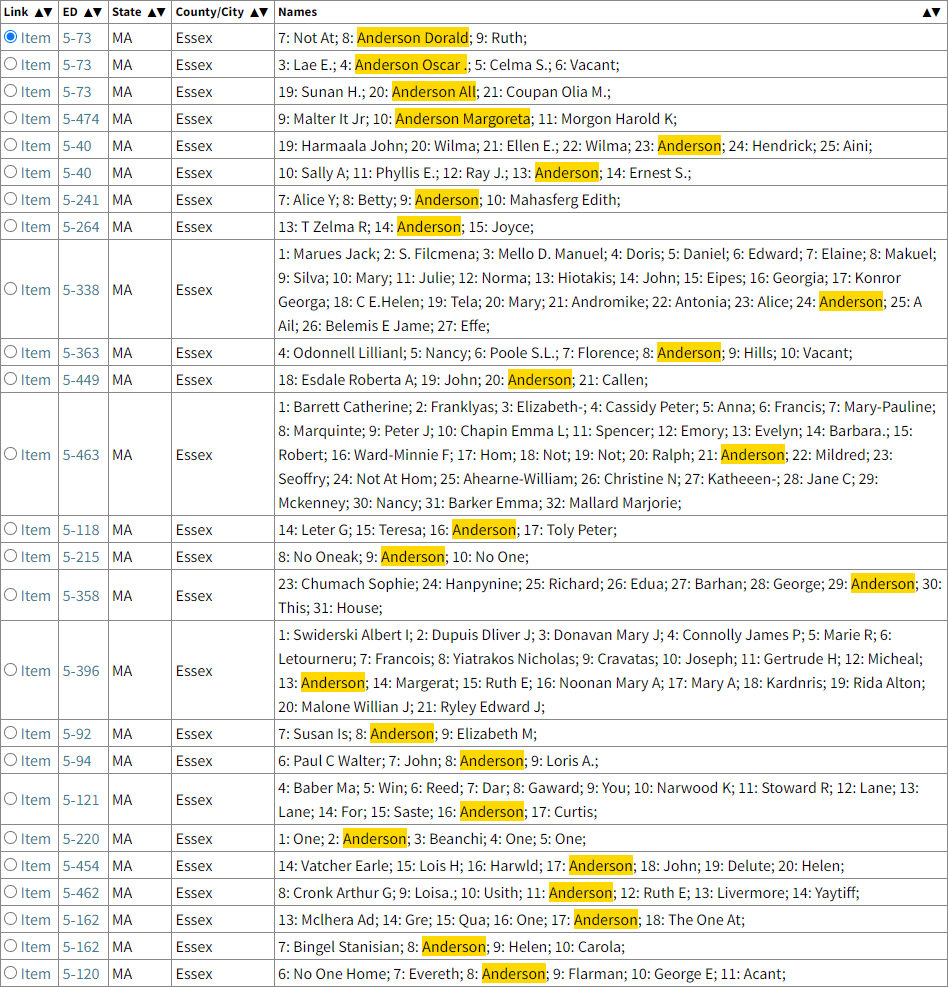
The summary table puts all the data I need to scan in a compact table at the top of the search results. The table is much easier to scan. It requires a lot less scrolling, and sometimes none. The marched names are highlighted and shown amongst other names near them in the enumeration. That provides very useful hints about who else was in the household.
There is a benefit that is not obvious: because ORA puts the matched names and some surrounding names in the Names column, I can use the browser's search feature (CTRL+F) to find entries of interest. When the matching text is below the summary table, I can stop searching as the text is either (1) a repeat of what I already found in the summary table, or (2) not of interest. For example, finding "George" in the summary table is helpful, but finding a random George in the "Extracted Names" list is not.
Using CTRL+F, I discover there is only one "George" in the summary results table. So, as expected after doing the search without ORA, I still don't find the correct George Anderson in the first 25 search results. I just found that out much faster than without ORA. I could repeat the process I used above where I moved from page to page until I got to page 7 and found the person of interest. There is a better way, however.
The ORA summary table is a great resource because I can scan it more easily. Let's take advantage of that by changing the number of results per page from 25 to 100, the maximum supported by the 1950 Census site.
The next trick I'll use is to sort the table. I know that the Saugus EDs are grouped together in the range 5-433 to 5-457. With the table sorted by ED, that will put any Saugus entries close together. Sweet!
With the table sorted by Enumeration District, I scroll down to the right range and I see there are only six entries of interest, and not a George (or variation of George) among them.

After quickly reviewing those six entries, I move to the next search results page and sort its summary table by the ED column. Scrolling down to the Saugus range of EDs, I find these entries:

Bingo! There is a George in a household with Dorothy!
The first column in the summary table is an "Item" link. I click the link to scroll the current page to the item with George and Dorothy, then I click the [Population Schedules] button to open the image viewer. After reviewing the page in the image viewer, I confirm that is the George Anderson I was seeking. Success!
Summary: Using ORA, I only had to scan 16 items, rather than hundreds, and it was easy and fast to scan those items.
Person Found?
After you find a person of interest in the census, ORA can help you transcribe the entry.
The OraPanel includes several fields that are not extracted from the census images including Sheet (sheet number) and other fields people often capture when entering census data in their genealogy database. You can right-click the fields to enter the data before using the OraPanel's copy or Auto Type features. This is a poor substitute for an actual transcription tool, but until transcriptions are available from online repositories, you may find it useful.
Another Issue
The example did not expose one of the other issues with the 1950 Census site.
Issue: When you search for a name and then open the image viewer, you cannot move forward or backwards in the image set.
For example, if you find the entry for a person, and the person is in a household that spans two pages, you can't move backwards or forwards to see the rest of the members of the household. The set includes only one page, the page with the target person.
To help with this issue, ORA provides links in the ED column to open a new page focused on the given Enumeration District. Those images sets include all the pages in the district and you can move forward or backward within the set. Make a note of the sheet number (upper right of image) before you open the district, then use the thumbnail images to move to the image.
Research is Easier with ORA
Until the major repositories provide transcriptions for the 1950 Census, the 1950 Census site provides the only seachable index. Using ORA, you can overcome some of the limitations of that site.
Please see the home page for more information about ORA. For a description of other features not discussed in this article, please see ORA's 1950 Census support page.